We propose a zero-shot approach for generating consistent videos of animated characters based on Text-to-Image (T2I) diffusion models.
Existing Text-to-Video (T2V) methods are expensive to train and require large-scale video datasets to produce diverse characters and motions.
At the same time, their zero-shot alternatives fail to produce temporally consistent videos with continuous motion.
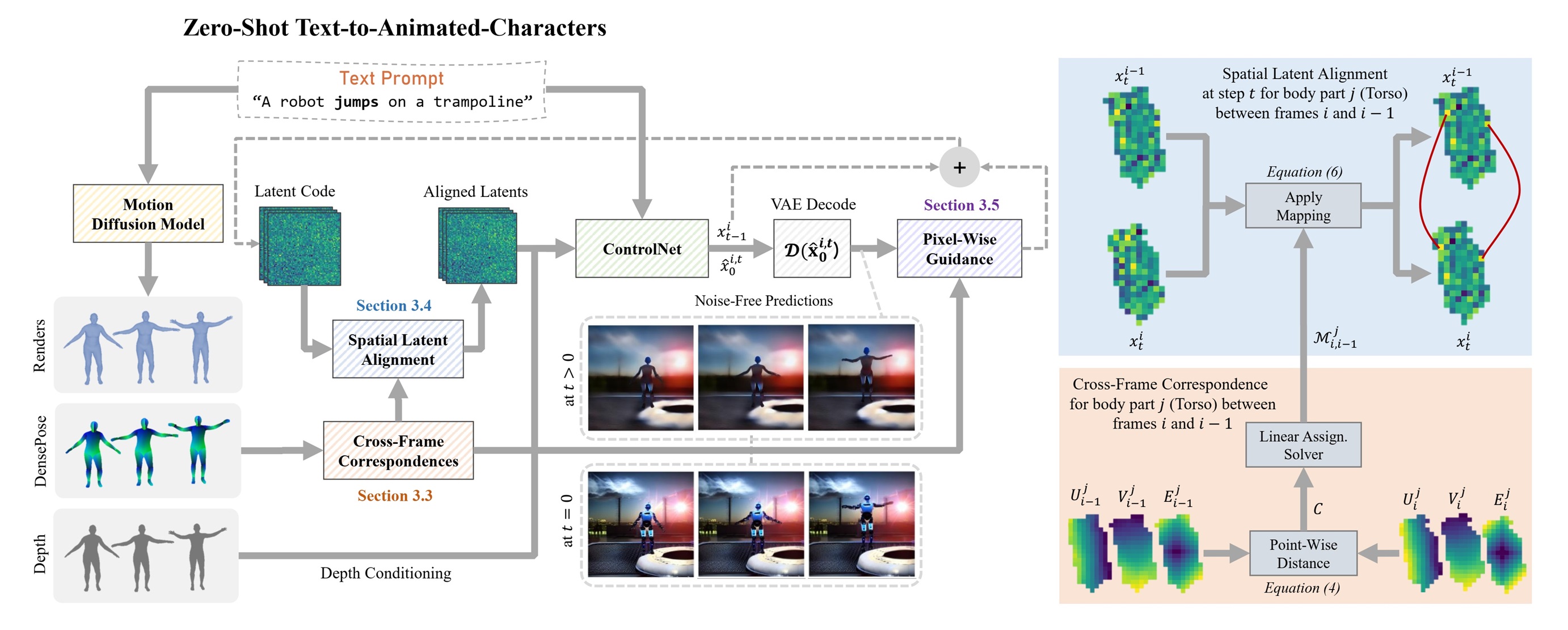
We strive to bridge this gap, and we introduce LatentMan, which leverages existing text-based motion diffusion models to generate diverse continuous motions to guide the T2I model.
To boost the temporal consistency, we introduce the Spatial Latent Alignment module that exploits cross-frame dense correspondences that we compute to align the latents of the video frames.
Furthermore, we propose Pixel-Wise Guidance to steer the diffusion process in a direction that minimizes visual discrepancies between frames.
Our proposed approach outperforms existing zero-shot T2V approaches in generating videos of animated characters in terms of pixel-wise consistency and user preference.