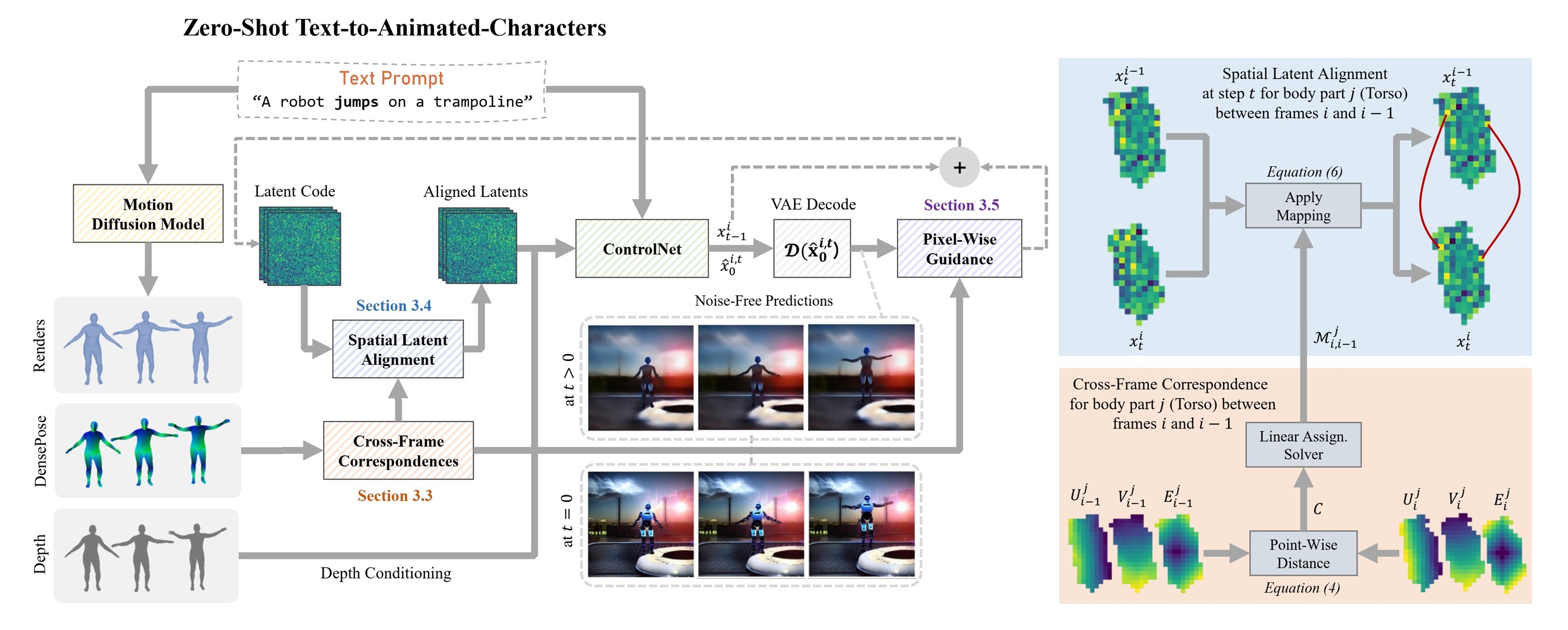
Summary

- Text-to-Image (T2I) diffsuion models can generate diverse images of human characters.
- However, generated images vary under any changes to the latent code or the guidance signal.
- This makes it difficult to use T2I models for directly generating videos of human characters without video tuning or guidance.
- We propose a new approach that employs motion diffusion models to generate motion guidance, while the video frames are generated using a pre-trained T2I diffusion model.
- Our approach can produce consistent videos of animated characters given only a textual prompt without requiring video guidance, training or finetuning.